Elasticsearch篇之入门
常用术语
文档
Document用户存储在es中的数据文档.(相当于数据库表中的一行)
索引
Index由具有相同字段的文档列表组成.(相当于数据库中的表,
es6.0以后index下的type只能有一个, 且官方声明以后会取消掉type这个概念)节点
Node一个
Elasticsearch的运行实例, 是集群的构成单元.集群
Cluster由一个或多个节点组成, 对外提供服务.
文档 Document
Document在es中是一个 Json Object, 由字段(Field)组成, 常见数据类型如下:- 字符串:
text(进行分词的字符串),keyword(不进行分词的字符串) - 数值型:
long,integer,short,byte,double,float,half_float,scaled_float - 布尔:
boolean - 日期:
date - 二进制:
binary - 范围类型:
integer_range,float_range,long_range,double_range,date_range
- 字符串:
- 每个文档有唯一的id标识
- 可以自行指定
- 也可以es自动生成
- 如下所示是一条Nginx日志在ES储存为一条文档(
Document), ES对其日志信息进行结构化处理, 包含多个字段(Field), 每个字段的字段名(Field Name)对应一个字段值(Field Value)
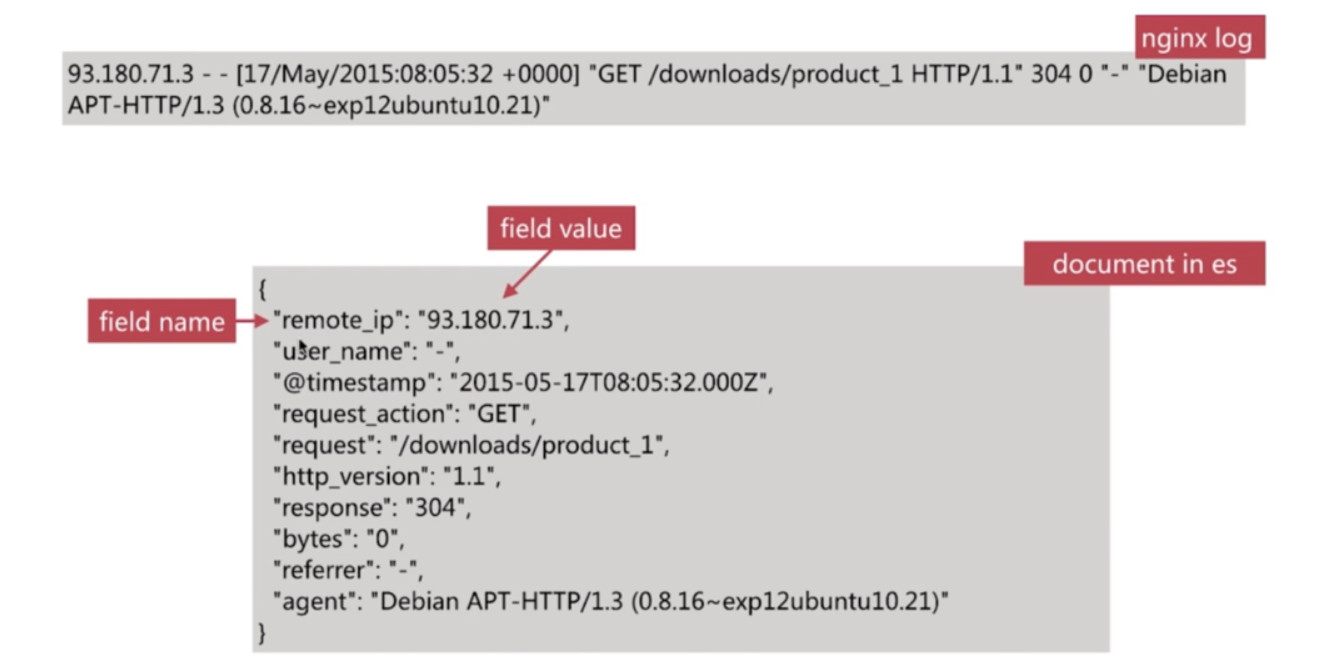
文档元数据 Document MetaData
- 每个Document都有一个文档元数据(Document MetaData), 用于标注文档的相关信息
_index: 文档所在的索引名_type: 文档所在的类型名_id: 文章唯一id_uid: 组合id, 由_type和_id组成(6.x中_type不再起作用, 所以在6.x版本中这个字段值和_id一样)_source: 文档的原始Json数据, 可以从这里获取每个字段的内容_all: 整合所有的字段内容到该字段, 默认禁用(官方不推荐使用)
索引 Index
- 索引中存储具有相同结构的文档(
Document)- 每个索引都有自己的mapping定义, 用于定义字段名和类型
- 一个集群可以有多个索引, 比如:
- nginx日志存储的时候可以按日期每天生成一个索引来存储, 方便维护
- nginx-log-2020-04-03
- nginx-log-2020-04-04
- nginx-log-2020-04-05
- nginx日志存储的时候可以按日期每天生成一个索引来存储, 方便维护
Rest API
- Elasticsearch集群对外提供RESTful API
- REST: REpresentational State Transfer (表述性状态转移)
- URI指定资源, 如Index, Document等
- Http Method指明资源操作类型, 如GET, POST, PUT, DELETE等
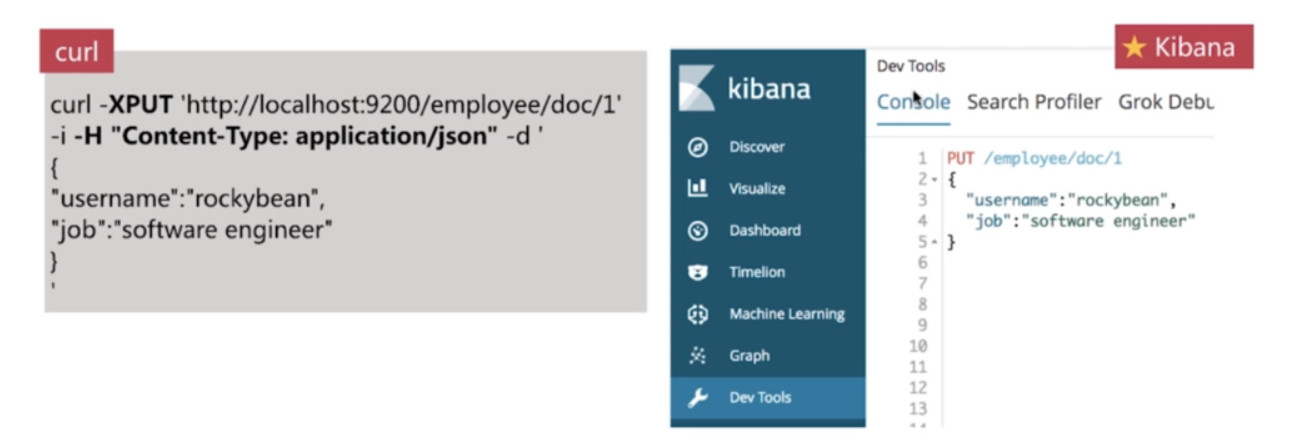
- 常用两种交互方式
- Curl命令行
- Kibana DevTools
索引 Index API
es有专门的Index API, 用于创建, 更新, 删除索引配置等
创建索引
PUT /{索引名}示例:
# request PUT /test_index # response { "acknowledged": true, "shards_acknowledged": true, "index": "test_index" }查看现有索引
GET /_cat/indices示例:
# request GET /_cat/indices # response red open account eIBKm9zfQhOZkW6tC1uyEA 5 1 1 0 5.4kb 5.4kb yellow open test_index XTzQRFtzRqK3B3EfULLrEg 5 1 0 0 1.1kb 1.1kb删除索引
DELETE /{索引名}示例:
# request DELETE /test_index # response { "acknowledged": true }
文档 Document API
es有专门的Document API
创建文档 (创建文档时, 如果索引不存在, es会自动创建对应的index和type)
指定id创建文档
# 其中类型名在6.x以后无实际作用, 并且将来版本要删除, 在这里可以任意指定, 一般指定无意义的doc PUT /{索引名}/{类型名}/{Id} { # 文档内容 }示例:
# request PUT /test_index/doc/1 { "username": "Jiavg", "age": 21 } # response # _version是为了在并行修改文档时, 防止发生错误 { "_index": "test_index", "_type": "doc", "_id": "1", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 1 }
- 不指定id创建文档
```
POST /test_index/doc
{
# 文档内容
}
```
示例:
```shell
# request
POST /test_index/doc
{
"username": "jlc",
"age": 20
}
# response
# 由于未指定id, es将会生成一个id
{
"_index": "test_index",
"_type": "doc",
"_id": "QzXQT3EBkfca6l6Y9SXp",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
```查询文档
指定要查询的文档id
GET /{索引名}/{类型名}/{id}示例:
# request GET /test_index/doc/1 # response # _source 储存了文档的原始数据 # 200 response { "_index": "test_index", "_type": "doc", "_id": "1", "_version": 1, "found": true, "_source": { "username": "Jiavg", "age": 21 } } # 404 response { "_index": "test_index", "_type": "doc", "_id": "2", "found": false }
- 搜索所有文档, 用到_search
```
# 不含查询条件 (查询所有文档)
GET /{索引名}/{文档名}/_search
# 包含查询条件 (查询符合条件的所有文档)
GET /{索引名}/{文档名}/_search
{
# 查询条件
}
```
示例:
```shell
# 不含查询条件 (查询所有文档)
# request
GET /test_index/doc/_search
# response
# took: 查询花费时间, 单位ms
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2, # 符合条件的总文档数
"max_score": 1,
"hits": [ # 返回的文档详情数据数组, 默认前10个文档
{
"_index": "test_index",
"_type": "doc",
"_id": "QzXQT3EBkfca6l6Y9SXp",
"_score": 1, # 文档的得分
"_source": {
"username": "jlc",
"age": 20
}
},
{
"_index": "test_index",
"_type": "doc",
"_id": "1",
"_score": 1,
"_source": {
"username": "Jiavg",
"age": 21
}
}
]
}
}
# 包含查询条件 (查询符合条件的所有文档)
# request
GET /test_index/doc/_search
{
"query": {
"term": {
"_id": 1
}
}
}
# response
{
"took": 23,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "test_index",
"_type": "doc",
"_id": "1",
"_score": 1,
"_source": {
"username": "Jiavg",
"age": 21
}
}
]
}
}
```更新文档
POST /{索引名}/{类型名}/{id} { # 更新文档内容 }
删除文档
DELETE /{索引名}/{类型名}/{id}
es允许一次创建多个文档, 从而减少网络传输开销, 提升写入速率
endpoint 为
_bulk, 如下:index和create同为创建文档, 不同的是index在创建文档时, 如果文档id已经存在, 则会覆盖相应的内容, 但是create在创建文档时,如果文档id已经存在, 则会报错。- 请求

响应

注意: 在使用
_bulk时,REST API端点为/ _bulk,并且期望使用以下以换行符分隔的JSON(NDJSON)结构:action_and_meta_data\n optional_source\n action_and_meta_data\n optional_source\n .... action_and_meta_data\n optional_source\nNDJSON: ndjson(New-line Delimited JSON)是一个比较新的标准,本身超简单,就是一个.ndjson文件中,每行都是一个传统json对象,当然每个json对象中要去掉原本用于格式化的换行符,而json的string中本身就不允许出现换行符(取而代之的是\n).
所以当请求的数据为普通Json时会发生错误.
示例:
# NDJSON # request POST _bulk {"index":{"_index":"test_index","_type":"doc","_id":1}} {"username":"Jiavg-1","age":5} {"update":{"_index":"test_index","_type":"doc","_id":"QzXQT3EBkfca6l6Y9SXp"}} {"doc":{"age":25}} {"create":{"_index":"test_index","_type":"doc","_id":3}} {"username":"znc","age":22} # response { "took": 52, "errors": false, "items": [ { "index": { "_index": "test_index", "_type": "doc", "_id": "1", "_version": 3, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 2, "_primary_term": 2, "status": 200 } }, { "update": { "_index": "test_index", "_type": "doc", "_id": "QzXQT3EBkfca6l6Y9SXp", "_version": 2, "result": "updated", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 1, "_primary_term": 2, "status": 200 } }, { "create": { "_index": "test_index", "_type": "doc", "_id": "3", "_version": 1, "result": "created", "_shards": { "total": 2, "successful": 1, "failed": 0 }, "_seq_no": 0, "_primary_term": 2, "status": 201 } } ] }
# 普通json
# request
POST _bulk
{
"index": {
"_index": "test_index",
"_type": "doc",
"_id": 1
}
}
{
"username": "Jiavg-1",
"age": 5
}
{
"update": {
"_index": "test_index",
"_type": "doc",
"_id": "QzXQT3EBkfca6l6Y9SXp"
}
}
{
"doc": {
"age": 25
}
}
{
"create": {
"_index": "test_index",
"_type": "doc",
"_id": 3
}
}
{
"username": "znc",
"age": 22
}
# response
{
"error": {
"root_cause": [
{
"type": "json_e_o_f_exception",
"reason": "Unexpected end-of-input: expected close marker for Object (start marker at [Source: org.elasticsearch.transport.netty4.ByteBufStreamInput@618ff58; line: 1, column: 1])\n at [Source: org.elasticsearch.transport.netty4.ByteBufStreamInput@618ff58; line: 1, column: 3]"
}
],
"type": "json_e_o_f_exception",
"reason": "Unexpected end-of-input: expected close marker for Object (start marker at [Source: org.elasticsearch.transport.netty4.ByteBufStreamInput@618ff58; line: 1, column: 1])\n at [Source: org.elasticsearch.transport.netty4.ByteBufStreamInput@618ff58; line: 1, column: 3]"
},
"status": 500
}
```
json和ndjson区别参考: https://blog.csdn.net/github_38885296/article/details/100915601es允许一次查询多个文档
endpoint为
_mget, 如下:




